
AIPR Debrief: Cross-Modal Foundation Models
Our Senior Machine Learning Engineer, Adam Francisco, shared detailed findings of this approach in greater detail at the AIPR Workshop in Washington, D.C. A formal white paper will be released in December.
The volume and diversity of remote sensing data available today is staggering, and it’s only accelerating. From fleets of Earth observation (EO) satellites to synthetic aperture radar (SAR) constellations and hyperspectral sensors, the modern world is being imaged from space with unprecedented temporal and spatial coverage.
Despite this abundance, making sense of it all remains a major challenge. Traditional machine learning approaches in remote sensing typically rely on large labeled datasets specific to a single modality or task. These models perform well within narrow contexts but fail to generalize across sensors and new targets of interest. Additionally, collecting labeled data for every modality and target of interest is expensive and often infeasible.
The Rise of Foundation Models
Foundation Models, large-scale, pretrained neural networks such as CLIP, GPT, and Segment Anything, have revolutionized computer vision and natural language processing. These models learn universal representations that can be fine-tuned or adapted for many downstream tasks with minimal additional data. At Bedrock Research, we utilize our own proprietary foundation model that is uniquely built for location-based intelligence.
Utilizing Every Relevant Data Type
Building in cross-modal capabilities takes our current approach to the next level. Our model solutions are trained to align information across different sensor types, such as optical EO imagery and SAR. This approach allows the model to understand that they depict the same underlying landscape or target, even if they look entirely different to a human in their original states. By learning a shared representation space, cross-modal models can bridge the gap between sensing modalities, enabling seamless transfer of insights between them.
At Bedrock Research, we have over 30 years of experience in procuring, registering, and organizing multi-sensor imagery at scale. Our automated systems have processed and co-registered data from a wide range of sensors across decades of observation. One such dataset we have procured, contains globally distributed, co-registered pairs of SAR and EO imagery from Capella Space and the Functional Map of the World (fMoW) dataset. Each image pair captures the same spatial footprint from different modalities, providing an ideal dataset for contrastive learning.

Four SAR images are passed into the trained encoder (left). Top 4 EO image embedding matches are displayed, with a green bounding box depicting a correctly matched embedding (middle). The four corresponding true EO matches for each SAR input image are displayed (right).Learning Shared Representations with Contrastive Learning
To train cross-modal encoders, we use contrastive learning, a powerful self-supervised technique that teaches models to bring related inputs closer together in the embedding space while pushing unrelated ones apart. In our case, EO and SAR images over the same geographic location form a positive pair, while EO and SAR images from different regions form negative pairs.
Through this process, the model learns to consistently encode the core physical and structural features of a landscape, independent of how it appears to a specific sensor.
An embedding refers to the numerical representation the model learns for an input image. Each embedding is a vector in a high-dimensional feature space. After training, two images of the same region, whether SAR or EO, will map to nearby points in embedding space.
Embeddings Reduced to Two Dimensions (Validation Set)
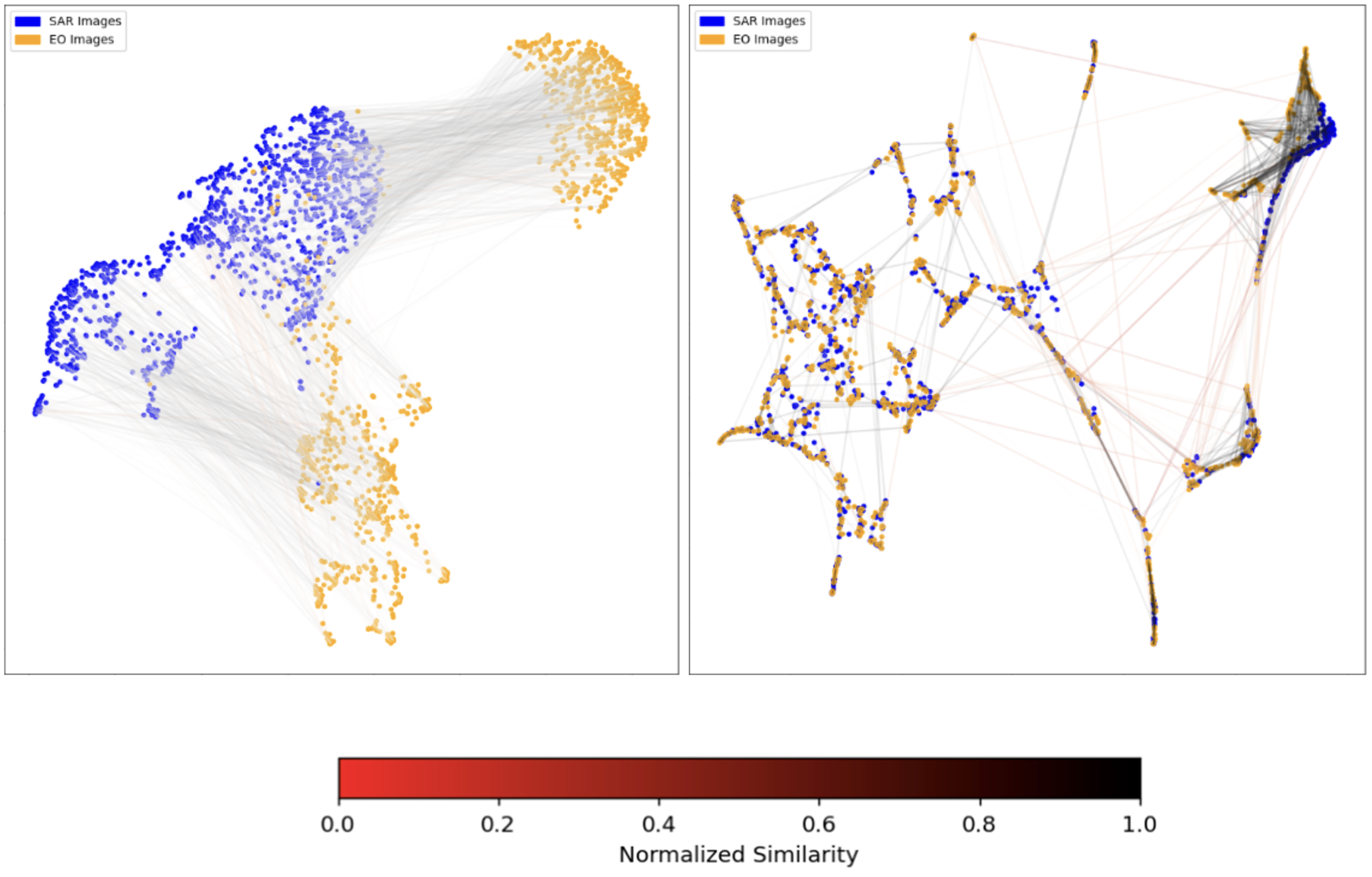
Left: Before Training / Right: After TrainingAs expected, if we pass the images through our models before training via contrastive learning, the embeddings mostly group by their modality type (EO or SAR). After training, the contrastive learning approach teaches the model to pair the images by their scene content rather than their modality. The lines in the image correspond to each matching EO and SAR image pair, after training these lines become extremely small (as the matching pairs are nearly on top of each other), however some outliers still exist. Interestingly, in the top right corner of the second image, a group/cluster of SAR and EO images exist nearby each other. Upon further exploration, the images of these embeddings are scenes of open water, where matching these to a specific image pair would be nearly impossible.
Another way to assess performance is to take an embedding from one modality and sort how well it matches with all the embeddings in the other modality. This way we can find how close to the top its true matching pair was in the sorted list. We can do this by creating a cosine similarity matrix, where we can compare all of the embeddings using the cosine similarity score.
Capella SAR Tech and fMoW Image Pair

We pass SAR images into our encoder after it has gone through the contrastive learning processes. From there, we show the top four cosine similarity scoring EO images. Highlighted in the green boxes are the true matching pairs for that specific SAR image (if they exist in the top four scoring EO images). On the far right are the true matching EO pairs. In this specific example, the first and last had its true matching EO image pair as its highest cosine similarity score. The second row did not find it in the top four matches and the third row found it as its second highest match. As expected, the SAR images with buildings all have buildings in their highest similarity scoring EO images, while the SAR scene of the port has ports in its top similarity scoring EO images. Plotting the least similarity scoring EO images shows scenes that are very different from the SAR landscapes as expected.
From Representations to Real-World Applications
Once trained, the cross-modal embeddings become a powerful foundation for a wide range of downstream applications for defense and intelligence, global supply chain, maritime, energy, construction, and environmental monitoring.
Instead of retraining models from the ground up for every new dataset or sensor, these pretrained embeddings are generalized and can be leveraged as inputs into downstream models with limited training data availability. Additionally, these downstream models can now utilize multiple modalities as they become available, helping fill gaps in understanding and provide persistent coverage. These final models can be used for downstream applications like change detection, object detection, and classification.