
How Bedrock Builds Foundation Models for GEOINT
At Bedrock Research, we aim to address a challenging problem in geospatial analytics: the ability to rapidly identify some critical target or activity amidst a flood of increasingly diverse overhead remote sensing data. Our customers are often looking for the proverbial “needle in the haystack,” and for the past couple of decades, the prevailing thought was that more imaging satellites or airborne systems across more modalities, coupled with more persistent coverage, would enable better intelligence. In practice, it has just created more hay.
To address this, Bedrock utilizes geospatial foundation models that fully exploit all available data, while also adapting quickly to specific needs and novel situations.
But what is a foundation model?
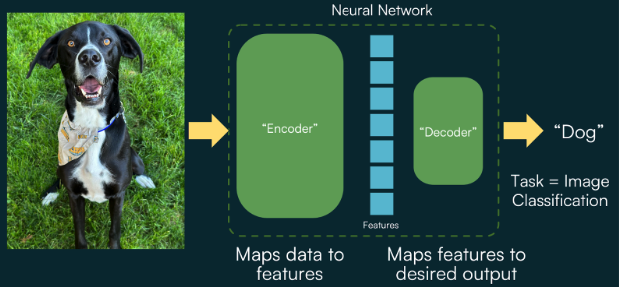
Recently, the term has become synonymous with deep learning Large Language Models (LLMs) like ChatGPT. But more generally, any type of data can be used to train a foundation model, not just language or text. In fact, the underlying technology behind foundation models is a direct extension of the surprisingly simple structure of almost all machine learning models and neural networks. They contain two main components that convert input data to some desired output:
An Encoder, which maps the input data to an abstract list of features
A Decoder, which converts that list of features to some specific output for the desired task, such as a category label for a classification
The crux of foundation models is that they can learn from massive amounts of data without requiring manual annotation. This is absolutely critical, as it allows any and all data ever collected to provide value, without creating many hundreds if not thousands of hours of work for a data labeler.
This is made possible through a clever innovation called masked autoencoding. In masked autoencoding, the decoder of the encoder-decoder pair has a very simple job: fill in the blanks of a masked version of the input data. This is often called self-supervised learning, because the “label”, or desired output, is a natural part of the input data, as opposed to a separate manual annotation created by a human for standard fully supervised learning.
For language processing, this concept of self-supervised learning was the piece that allowed LLMs to become mainstream. By using all available text (e.g. news articles, Wikipedia, forum posts, public domain works, etc.), the model learns critical features of language and relationships between words, subjects, and contexts during training. Blocks of text have random words or phrases masked, and the encoder’s job is to map the present words to a feature space that lets the decoder predict what words should fill in the blanks. By training on many millions of examples and providing accuracy of the predicted words back to the model, it slowly learns essentially all there is to know about language!
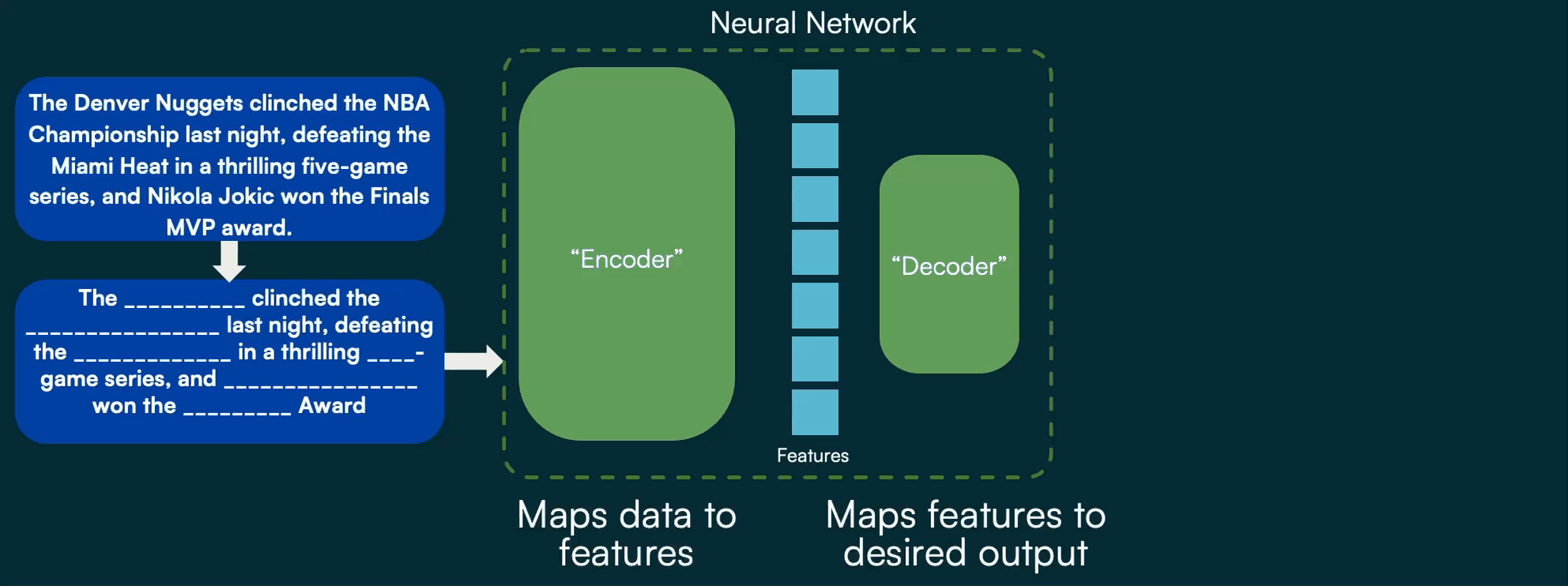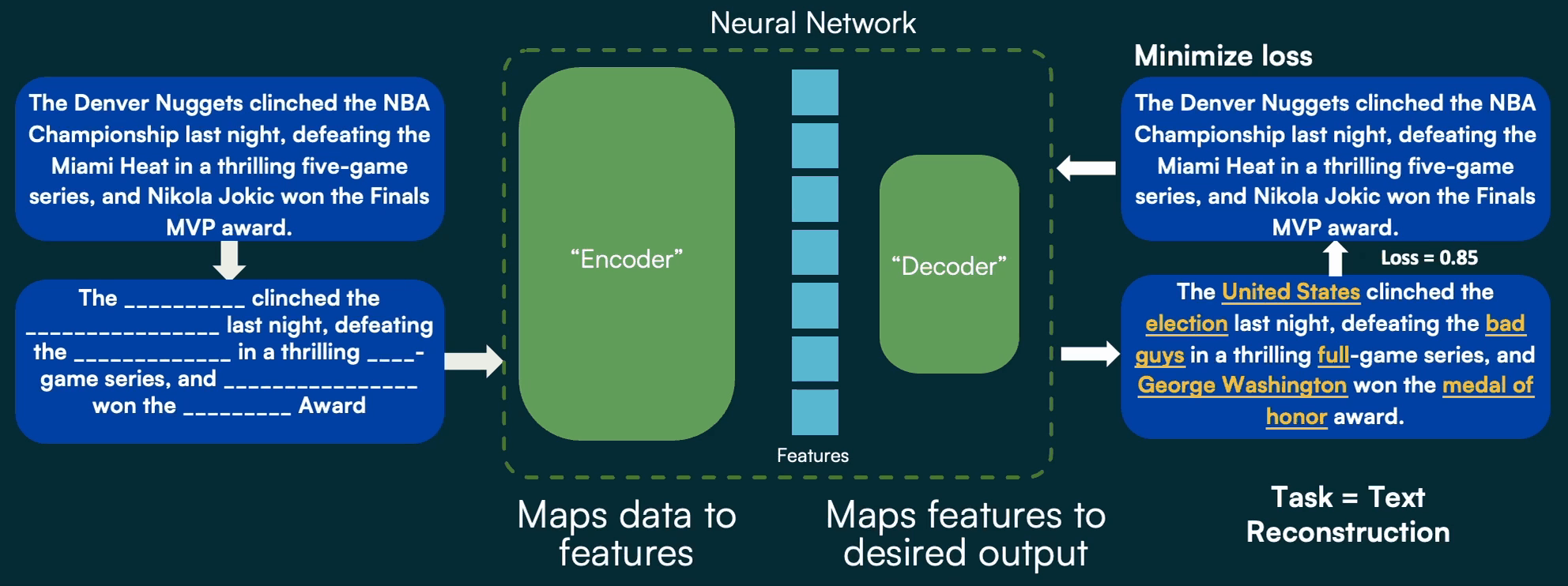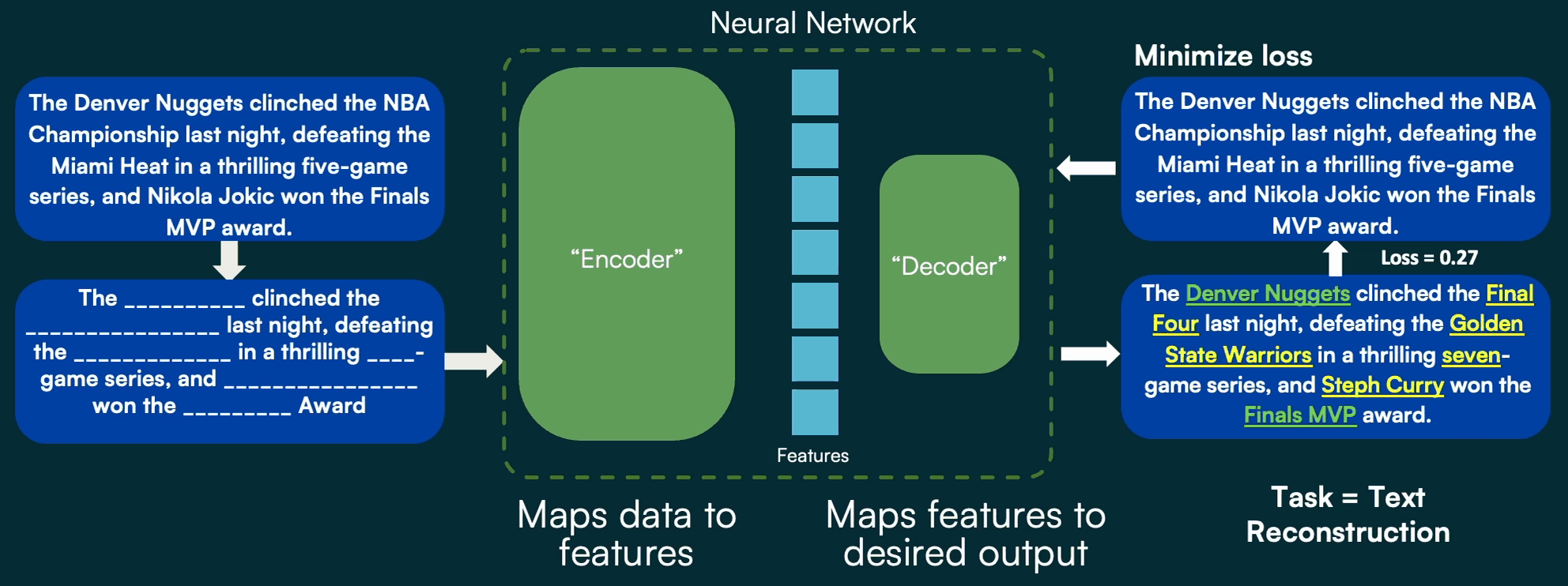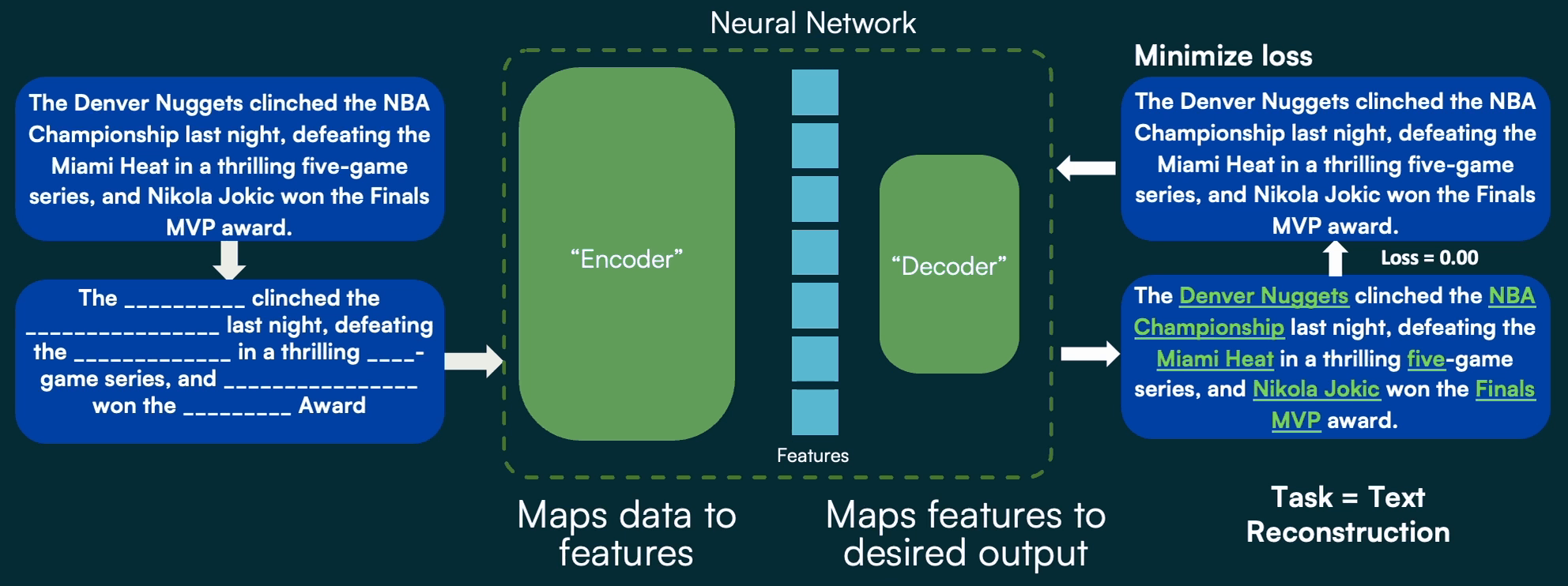
More recently, researchers uncovered clever manipulations to the underlying components of this encoder and decoder that allow for the exact same approach to be applied to image processing. As a result, we can utilize the massive volumes of data that typically have caused headaches for consumers and analysts (the mountain of hay they have to sift through to find what they actually care about) to our advantage, by feeding all of them into our model to help it learn features and contexts present in diverse imagery.
With many millions of images, we can train an encoder that can convert essentially any image into a very detailed feature space, and a decoder that uses those features to fill in the blanks of the masked portion of the input:
In practice, the reconstruction of a randomly masked image isn’t particularly useful on its own. But using this self-supervision during training allows us to build an encoder that can translate any image into a high-value, versatile feature space. This encoder is an important part of our geospatial foundation model, and provides incredible, lasting value by doing the heavy training lift up front. Having a high-quality encoder makes tasks like object detection, classification, or change detection, faster and easier.
Now all we need is a new decoder for that task. Since we have already trained our encoder, we only need a little bit of data and labels from the task of interest for our new decoder to learn how to convert the encoded features into the desired output.
This approach to foundation model training using self-supervised learning lets us use our specialized machine learning models for almost any use case in remote sensing or overhead image processing.